저번 글에 이어 이번에는 가격과 작가 정보를 추가로 얻어와 csv파일과 xlsx 파일로 저장을 해보겠다.
우선 작가와 가격정보는 크롬의 개발도구를 이용하여 selector를 얻고 동일하게 정보를 가져온다.
소스코드 -
import requests
from bs4 import BeautifulSoup
def get_name(url):
name = list()
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.select("div.info_area > div.detail > div.title > a > strong"):
name.append(anchor.get_text())
return name
def get_price(url):
price = list()
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.select("div.info_area > div.detail > div.price > strong.sell_price"):
price.append(anchor.get_text())
return price
def get_author(url):
author = list()
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.select("div.info_area > div.detail > div.pub_info > span.author"):
author.append(anchor.get_text())
return author
url = 'http://www.kyobobook.co.kr/categoryRenewal/categoryMain.laf?perPage=20&mallGb=KOR&linkClass=01&menuCode=002'
name = get_name(url)
price = get_price(url)
author = get_author(url)
print(name)
print(price)
print(author)
-결과

정상적으로 잘 출력이되는걸 볼 수 있다.
이제 이 데이터들을 하나로 합쳐 엑셀이나 csv 파일로 저장을 해보자.
우선 파이썬 라이브러리 pandas를 이용한다.
-소스코드
import requests
from bs4 import BeautifulSoup
import pandas as pd
###
생략
###
l = list()
for i in range(0, len(name)):
l.append([name[i], author[i], price[i]])
df = pd.DataFrame(l, columns=['제목', '작가', '가격'])
print(df)위 소스코드를 추가하여준다.
-결과
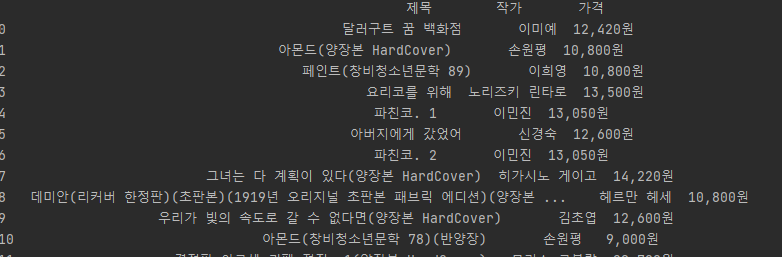
데이터프레임 형태로 출력이 되는것을 볼 수 있다.
이제 이 데이터프레임을 xlsx파일과 csv파일로 저장을 할려면 openpyxl가 필요하다. 그리고
다음과 같은 소스코드를 추가하여준다.
-소스코드
import requests
from bs4 import BeautifulSoup
import pandas as pd
from openpyxl import Workbook #csv파일만 생성할때는 필요없음
###
생략
###
df.to_csv("data_csv.csv") #df.to_csv("경로/파일명.csv")
df.to_excel("data_xlsx.xlsx") #df.to_excel("경로/파일명.csv")-결과
xlsx파일
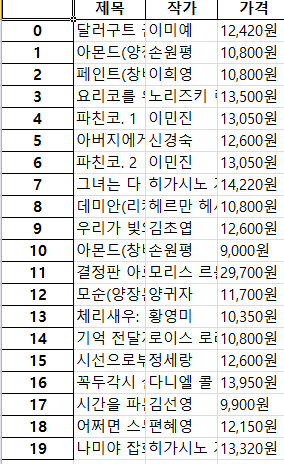
csv파일

출력을 보면 csv 파일이 이해할 수 없는 언어로 출력되는걸 볼 수 있다.
이유는 인코딩 방식이 다르기 때문인데 인코딩 방식을 바꾸고 csv파일을 깔끔하게 정리를 할려면 다음과 같은 소스코드로 변경하면 된다.
df.to_csv("data_csv.csv", header=False, index=False, encoding='euc-kr') #df.to_csv("경로/파일명.csv", header=1행(제목, 작가, 가격), index=(번호))
결과
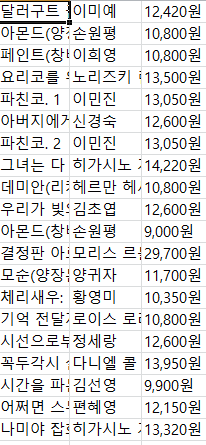
-최종 소스코드
import requests
from bs4 import BeautifulSoup
import pandas as pd
from openpyxl import Workbook
def get_name(url):
name = list()
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.select("div.info_area > div.detail > div.title > a > strong"):
name.append(anchor.get_text())
return name
def get_price(url):
price = list()
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.select("div.info_area > div.detail > div.price > strong.sell_price"):
price.append(anchor.get_text())
return price
def get_author(url):
author = list()
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
for anchor in soup.select("div.info_area > div.detail > div.pub_info > span.author"):
author.append(anchor.get_text())
return author
url = 'http://www.kyobobook.co.kr/categoryRenewal/categoryMain.laf?perPage=20&mallGb=KOR&linkClass=01&menuCode=002'
name = get_name(url)
price = get_price(url)
author = get_author(url)
l = list()
for i in range(0, len(name)):
l.append([name[i], author[i], price[i]])
df = pd.DataFrame(l, columns=['제목', '작가', '가격'])
df.to_csv("data_csv.csv", header=False, index=False, encoding='euc-kr') #df.to_csv("경로/파일명.csv", header=1행(제목, 작가, 가격), index=(번호))
df.to_excel("data_xlsx.csv")
'프로그래밍 > 파이썬' 카테고리의 다른 글
| numpy 사용하기 벡터, 행렬, 배열 (0) | 2021.06.16 |
|---|---|
| 파이썬으로 웹 크롤링하기(3) 동적 페이지 (0) | 2021.03.23 |
| 파이썬으로 웹 크롤링 하기(1) 정적인 웹 페이지 (0) | 2021.03.22 |
| 2. 파이썬 자료구조 튜플 (0) | 2021.02.17 |
| 1.파이썬 자료구조 리스트 (0) | 2021.02.14 |

